ipsetの各種データ形式(hash,bitmap,list)
ipsetのデータ形式には大きく分けてhash,bitmap,listの3種類があります。今回はそれぞれの特徴をカーネル内のデータ構造も含めて解説したいと思います。
hash
まずは、一番多く使われているであろうhashセットです。
登録したエントリは名前のとおりハッシュ形式で保持します。ハッシュなので検索も高速に行えます。netfilter(iptables)に大量のエントリを登録するとリニアサーチで遅くなるので、ipsetでまとめて登録するのが推奨されるのはこのためです。
ハッシュ内に持つデータの種類によって、hash:ip,hash:mac,hash:ip,port等いろいろな形式のセットがありますが、よく使われるのはIPアドレスを保持するhash:ipやネットワークアドレスを保持するhash:netあたりかと思います(*1)。
ただのハッシュではありますが、IPアドレスにマッチするネットワークアドレスを検索するhash:netではハッシュ検索に少し工夫がされているので解説したいと思います。
hash:ipでは登録されているエントリはIPアドレスで、検索キーとなるIPアドレス(SourceIP,DestinationIP)と同じ形式のデータなのでハッシュによる検索は単純です。
一方、hash:netのようにネットワークアドレスを登録するセットの場合、ハッシュエントリの形式(ネットワークアドレス)と検索キーとなるIPアドレス(SourceIP,DestinationIP)で形式が異なるため、単純なハッシュ検索だけでネットワークアドレスとのマッチングを取ることはできません。
例)
セットに10.0.0.0/24のエントリが登録されているとして、SourceIP 10.0.0.1のIPアドレスで検索しようにもハッシュキーを計算する術がないため、結局ハッシュ内の全エントリを調べる必要がある。
このためhash:netではIPアドレス10.0.0.1を10.0.0.1/32から10.0.0.0/1までプレフィクス長を変化させながら、ネットワークアドレスでハッシュ検索を繰り返すことで、マッチするエントリがないか検索するようになっています。
上記の例では10.0.0.0/24での検索時点でハッシュ内のエントリにマッチします。
ただこの方式では、一回のマッチングで最悪IPv4なら32回、IPv6なら128回のハッシュ検索が繰り返されることになり無駄が多くなります。これを避けるためにhash:netではデータ構造に工夫がされており、ハッシュに登録されているネットワークアドレスのプレフィクス長ごとのエントリ数を保持するようになっています(詳細は下で説明)。
このため、実際にはハッシュ内に存在するプレフィクスでしかハッシュ検索しないので、32回ハッシュ検索を繰り返すことはありません。
図1にhash:net(inet)のカーネル内のデータ構造の概要を示します。
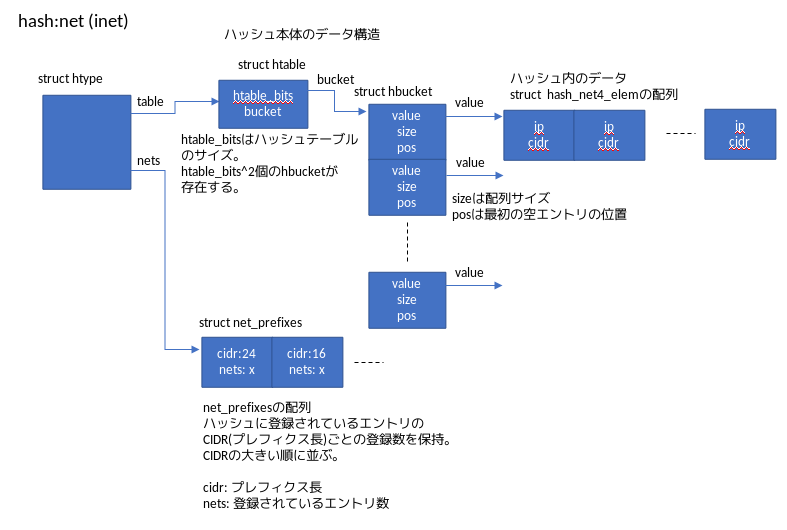
[データ構造の解説]
hash:net(inet)のデータの大元はstruct htypeになります。struct htableがハッシュテーブルの実体になります。ハッシュのデータ構造自体は普通の構造で、ハッシュサイズの分だけhbucketが並んだ配列があり(計算されたハッシュキーによりどのhbucketを使うかが決まる)、各hbucketのvalueの先にハッシュに登録したデータが並んでいる形になります。ハッシュエントリはstruct hash_net4_elemでipにネットワークアドレス、cidrにプレフィクス長が保存されています。
ネットワークアドレス検索用に工夫されているのが、htype構造体のnetsになります。
htype.netsの先にはstruct net_prefixesの配列があり、ハッシュに登録されているネットワークアドレスのエントリ数をプレフィクス長ごとに分けて保持するようになっています。
このため、10.0.0.1/32から10.0.0.1/1までプレフィクス長を変化させながらハッシュ検索を繰り返す際、ハッシュ内にないプレフィクス長での検索を省くことができるようになっています。
このあたりの検索処理はカーネルのip_set_hash_gen.hのmtype_test()とかmtype_test_cidrs()を読めば理解できます。
(*1) hash:netには/32のプレフィクスのエントリも登録でき、hash:ipを内包できるのでわざわざhash:ipを使う人はいないかもしれませんが。
bitmap
次はbitmapセットです。
bitmapセットではセット作成時にIPアドレスやポートの範囲を定義し、その範囲内でエントリの登録/削除を行います。
セット内のデータは名前のとおりbitmapで管理されます。データ構造をみた方がイメージしやすいと思うので図2にbitmap:ip(inet)のカーネル内のデータ構造の概要を示します。
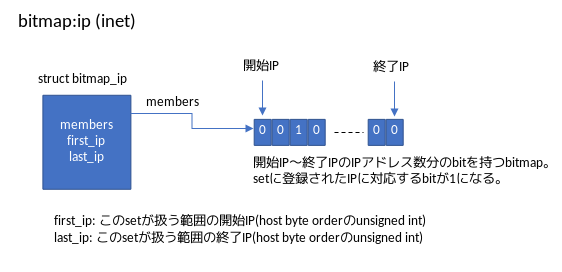
struct bitmap_ipがbitmap:ipセットの大元になります。membersの先に範囲分のbitを持つbitmapが存在します(例:10.0.0.0~10.0.0.255の範囲を扱うなら256bit分)。セットに登録されたIPに対応するビットが1になります。
bitmapセットの設定例
ipset create bitmaptest bitmap:ip range 10.0.0.0/24 ↑10.0.0.0-10.0.0.255の範囲を扱うセットを作成。 ipset add bitmaptest 10.0.0.10 ipset add bitmaptest 10.0.0.128/25 ↑10.0.0.128-10.0.0.255のIPアドレス(128個)をまとめて登録。 hash:netと異なりbitmapにはネットワークアドレスという概念は存在しないので、 10.0.0.128-10.0.0.255の128個のIPがばらばらに登録される(128個分のbitが1になる)。
セットに登録されたエントリのデータをbitmapで持つため検索は高速に行えます。作りもハッシュより単純なので検索も高速なはずです。
短所としては、bitmapでデータを持つので大きい範囲を扱うとメモリの使用量が大きくなります。このため、範囲の最大サイズはIPSET_BITMAP_MAX_RANGEに制限されており、
#define IPSET_BITMAP_MAX_RANGE 0x0000FFFF
のように定義されているので、bitmap:ipの場合、プレフィクス長でいうと/16のネットワーク範囲が指定できる上限となります(*2)。
あまり大きいIP範囲を指定できないせいか、IPアドレスのサイズが大きいIPv6には対応していません。
個人的にはbitmap:ipについては正直使いどころがあまりなく、セット内にIPを保持したいならhash:netの方を使った方がいいと思います。おそらくbitmapセットはIP範囲を扱うよりもport範囲を扱うbitmap:portでの使用を想定しているのだと思います。
ただ、サーバー運用上、ポートをあれこれ大量に開けることはないので、それならばnetfilterに個別にエントリ登録すればすむような気もして、私はbitmapセットを実運用で使ったことはありません。
(*2) IPSET_BITMAP_MAX_RANGEが65535なので範囲の幅が65536の/16ネットワークのセットは作成できないように見えますが、bitmap:ipでは範囲上限がIPSET_BITMAP_MAX_RANGE + 1と調整されているので実際には作成できます
list
最後にlistセットです。
listセットはlist:setのみです。list:setは定義済みのipsetのセット名を登録します。名前のとおりリスト形式でセット名を管理します。
マッチング時はリストに登録されたセットを再帰的に評価していきマッチした時点で終了となります。私は使ったことがありませんが、セットをグループ化して管理するのにはいいかもしれません。
まとめ
なぜこの記事を書いたかというと、IPアドレスからマッチするネットワークアドレスを検索するには、BSD系OSのルーティングテーブル検索のようにRadix Treeによるツリー検索で行うイメージがあり、そもそも、hash:netでどのようにハッシュ検索を行っているのか以前から少し気になっていました。そこで今回調べてみようと思ったのがきっかけです。ついでにbitmapの実装についても軽く調べてみました。データ構造がわかるとmanを読んでいまいちピンとこない部分も理解できるようになると思います。
投稿日:2019/07/08 15:22
タグ: Linux